SQL — The math behind database pt1
A brief understanding of what we don't see in databases
Introduction
This is the first of a series of articles which I will develop about SQL tips and tricks for those which are starting now on database area, and this desire was due mainly to the fact that I realize that many colleges and courses , barely pay enough attention to the database, which is the great silent villain for system performances.
Dimitri Kravtchuk, Oracle performance architect, in his performance presentation that you can check here, says that 95% of slowdown problems are always related to the application layer of the software and not to servers and databases.
And this all happens, mainly due to the lack of experience and knowledge (no one born knowing things), and for this reason, I will indicate here, some books that made me learn things in a more correct way.
What is Structured Query Language or SQL?
The SQL language is a standard from ISO (International Organization for Standards) and ANSI (American National Standards Institute) which still continues to evolve (the last version I followed was updated in 2011) and it is used to manipulate information in the database. There are some cases where we come across to specific languages to each database and which is very similar to SQL because it is an ISO standard, for example Microsoft’s T-SQL and Oracle’s PL/SQL, for this reason always :
- Choice to use the standard, regardless of the database you are using. Only use non sql standard for a very important reason and that only if it really benefits for you, on the other hand, if one day you need to migrate platform, your impact will be minor if you are using standard SQL.
- For example, in T-SQL, it accepts 2 types of “not equals” <> and != , the first is standard and the second is not.
SQL é baseado no modelo relacional matemático
The relational model is a mistake because, for many folks, the database is relational due to the table relation (foreign keys), but the term comes from mathematics.
According to the creator of the mathematical theory, Georg Cantor
“Sets is any set M of a definition (total), distinct objects m (which are called elements of M) of our perception or our thought”
Which means, if M is a set of cars, we can say that every car contains tires, windows, doors, which are its m elements.
By definition: We consider that nobody interacts with an element only of a set, on the contrary, we interact with the whole, that is, hardly anyone uses a car and only interacts with the tire.
Another branch of mathematical model is predicate logic. To filter, ensure integrity, etc… The relational model uses the logic of predicates as one of its steps too.
Examples of predicates:
- Salary greater than 5000;
- Age over 20;
- Name equal to ‘Larissa’;
The anatomy of a query, how does a SELECT statement work?
Now that we understand the basics of database’s math, we’ll get into a little more advanced topic, which I hope you have a bit of knowledge about running a query on a database. We will now talk about how SQL Engine works, which is responsible for all mathematical interpretation in the insertion and retrieval of data in databases.
To explain the step-by-step, let’s consider the query below as an example from this article, to methodically explain what a SQL Engine would perform this command.
SELECT count(*) as qty, city
FROM students
WHERE UF= ‘SP’
GROUP BY city HAVING count(*) > 1
ORDER BY city
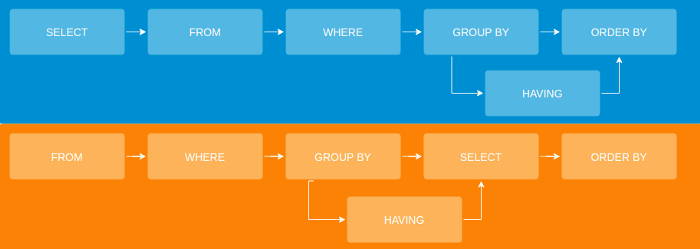
1 — FROM
The first procedure performed is analysis of the data source, which means, the TABLE where we are storing data, disregarding some configuration exceptions such as paging and amount of memory allocated for queries, in this step the engine tries to recover as much as possible of existing information in the table for later use, that is, even with the filter ( WHERE ) activated, all rows would be retrieved to the server memory.
2 — WHERE
The second phase consists of filtering the lines that really make sense to us, for this we point WHERE the data we need is. Only values that return true will be fetched, thus respecting the math of predicate logic. As we pointed in the query above, we need the lines WHERE the UF was true for the SP value.
3 — GROUP BY
In this part, we deal with combinations of elements from the origin table. Each row will be grouped by according to the grouping rule imposed. The query we use is grouping by city, visually the example would be


4 — HAVING
This phase is responsible for filtering data, however, we will only use HAVING after a GROUP BY. In our case, HAVING is using a predicate of COUNT (*) > 1, it is filtering GROUPS by city that meets more than one data confirmed.
- What’s the big difference between WHERE and HAVING? WHERE evaluates the rows before they are grouped, whereas HAVING only evaluates a grouped result
5 — SELECT
The fifth part of the processing is responsible for SELECT the right data. In this phase, we divided in 2 steps.
The first step would be listing and return the columns we need to display from the table.
The second step is using functions to transform data for each column individually, for example the COUNT() function in our example.
6 — ORDER BY
This phase is optional, if we want to ORDER the way the result will be displayed. In our case, we see that ordination occurs by city.
It may happen that you try to order a column that has an alias
SELECT column as 'ALIAS'in this case, as we studied above, the ORDERING occurs after the SELECT, so the expression (alias) has already been validated before and should be used in ORDER BY.
Another important point of using ORDERING is that it adds an extra cost for query processing, in cases where the order is not important, it is advisable not to use the ordering unnecessarily.
7 —The statement
In blue, the statement as we write, in orange how it is executed.